

・「ファイルサーバーのどこかにあるはずなのに見つからない」
・「あの件は◯◯さんしか知らない」
多くの企業で日々の業務時間の約20%が「情報の検索」に費やされていると言われています。
週5日のうち丸1日を「探しもの」に使っている計算です。
この非効率的な業務を劇的に解消する切り札として、「生成AIによる社内ナレッジ活用」が注目されています。
しかし、
・「ChatGPTと何が違うのか?」
・「機密情報は漏れないのか?」
といった疑問や不安も尽きません。
本記事では、社内ナレッジ活用に特化した生成AIの導入について、仕組みからリスク対策、具体的な進め方までを網羅的に解説します。
この記事でわかること
従来の検索システムと「生成AI検索」の決定的な違い
社内データを安全に活用する技術「RAG」の仕組み
導入企業の具体的な活用事例(ヘルプデスク・営業・技術承継)
セキュリティリスクとハルシネーション(嘘)への対策
失敗しないための導入ロードマップとデータ整備の重要性
1. なぜ今、社内ナレッジ活用に「生成AI」が必須なのか?
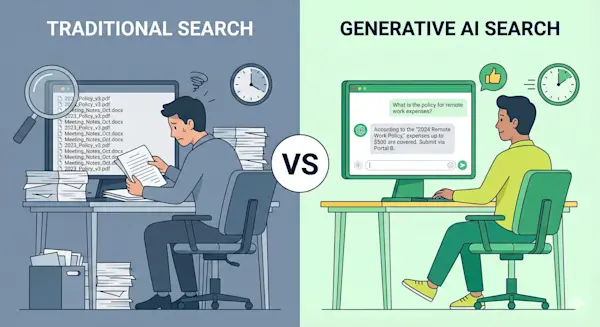
従来のキーワード検索型システム(全文検索エンジンなど)と、生成AIを活用した検索システムには、決定的な違いがあります。
それは「単語の一致」を探すか、「意味」を理解して答えるかの違いです。
従来の検索システムの限界
これまでの社内検索は、ユーザーが入力したキーワードが文書内に含まれているかどうかを判定していました。
例えば「交通費 申請」と検索した場合、その単語が含まれる規定集のPDFがヒットするだけです。
ユーザーはそのPDFを開き、Ctrl+Fで再度検索し、該当箇所を読み込んで自ら解釈する必要がありました。
生成AIがもたらす「対話型」の革命
一方、生成AIはユーザーの意図(インテント)を理解します。
「新幹線で出張したんだけど、領収書なくした場合はどうすればいい?」と自然言語で質問すれば、AIは社内規定を読み込み、「領収書紛失時は『出張費精算書』の備考欄に理由を記載し、上長の承認を得てください」といった具体的な回答を生成します。
つまり、「探すツール」から「答えを教えてくれるアシスタント」へと進化したのです。
これにより、情報検索にかかる時間は大幅に短縮され、社員は本来の創造的な業務に集中できるようになります。
用語解説:セマンティック検索
単なるキーワードの一致ではなく、言葉の「意味」や「文脈」を理解して検索する技術。
これにより、「車」と検索して「自動車」や「車両」が含まれる文書を探し出すことが可能です。
私が以前支援した製造業のクライアントでは、膨大な技術マニュアルの中から必要な数値を探すのに若手社員が毎日1時間を費やしていました。
生成AI導入後は、チャットに質問するだけで30秒で回答が得られるようになり、「まるでベテラン社員が隣にいるようだ」と現場の空気が一変したのを目の当たりにしました。
2. 社内データをAIに学習・参照させる仕組み(RAGとは)
社内ナレッジを活用する際、最も誤解されやすいのが「AIに社内データを学習(トレーニング)させる」という考え方です。
実は、セキュリティやコストの観点から、学習ではなくRAG(検索拡張生成)という技術を使うのが現在の主流です。
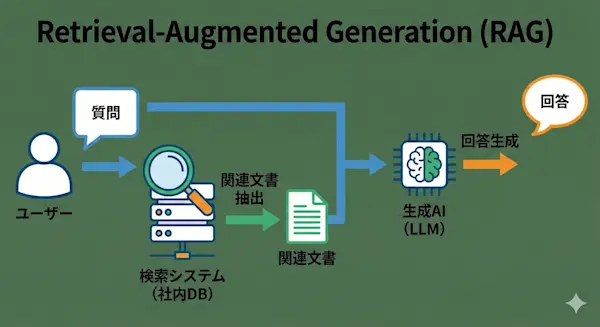
RAG(Retrieval-Augmented Generation)の仕組み
RAGとは、簡単に言えばカンニングペーパー付きの試験のようなものです。
下記の手順のようにAIが社内文書や最新の外部情報などの信頼できる情報を検索して活用する技術のことを言います。
質問: ユーザーがAIに質問する。
検索: システムが社内データベースから、質問に関連する文書(カンニングペーパー)を探し出す。
生成: AIはその文書の内容を読み込み、それを基に回答を作成する。
この仕組みであれば、AI自体に知識を記憶させる必要がないため、情報漏洩のリスクを抑えつつ、常に最新の社内規定やマニュアルに基づいた回答が可能になります。
ファインチューニングとの違い
「AIに追加学習(ファインチューニング)させればいいのでは?」と思うかもしれません。
しかし、ファインチューニングには以下のデメリットがあります。
コストが高い: 追加学習には膨大な計算リソースが必要。
更新が困難: 社内ルールが変わるたびに再学習が必要。
忘却リスク: 新しいことを覚えると、元々の賢さが損なわれることがある。
そのため、情報の鮮度が重要で、低コストに運用したい社内ナレッジ活用においては、RAGが最適解となります。
用語解説:ベクトルデータベース
テキストデータを数値(ベクトル)に変換して保存するデータベース。
これにより、AIは「言葉の意味的な近さ」を計算し、関連情報を高速に検索できるようになります。
ある企業で「AIに全部覚えさせたい」という要望がありましたが、人事異動や規定変更の頻度をヒアリングした結果、「毎月再学習させるコストは払えない」という結論に至りました。
RAG方式を採用することで、ファイルをフォルダに入れるだけでAIが即座に認識できる環境を構築し、運用コストを1/10以下に抑えることができました。
3. 生成AIによるナレッジ活用の具体的なユースケース

社内ナレッジ×生成AIの活用は、単なる「Q&A」に留まりません。
部門ごとの具体的な活用シーンを見てみましょう。
1. 【バックオフィス】ヘルプデスクの自動化
総務や人事、情シスには「パスワードの変え方は?」「年末調整の期限は?」といった同じような質問が殺到します。
これらを社内規定やマニュアルを読み込ませたAIに代行させることで、担当者の負担を劇的に減らせます。
2. 【営業・マーケティング】提案書作成支援
過去の提案書や成功事例(ベストプラクティス)をAIに参照させます。
「A社向けのセキュリティ提案書のドラフトを、過去のB社の事例を参考にして作成して」と指示すれば、自社の強みや勝ちパターンを踏襲した提案書の骨子が数秒で完成します。
3. 【技術・開発】暗黙知の継承(技術伝承)
ベテラン社員が書いた技術日報やトラブルシューティング記録をデータ化します。
「過去にこのエラーが出た時の対処法は?」と聞けば、担当者が退職していても、残されたドキュメントから解決策を提示してくれます。
これは「属人化」の解消に極めて有効です。
営業部門での導入事例ですが、新人営業マンが「顧客からの突っ込んだ技術的な質問」に即答できず持ち帰ることが課題でした。
過去の技術資料を参照できるAIアプリをスマホに入れたことで、商談中にその場で回答できるようになり、受注率が目に見えて向上したケースがあります。
4. 導入時に直面するリスクと対策(セキュリティ・精度)
企業利用において避けて通れないのが「セキュリティ」と「ハルシネーション(もっともらしい嘘)」の問題です。
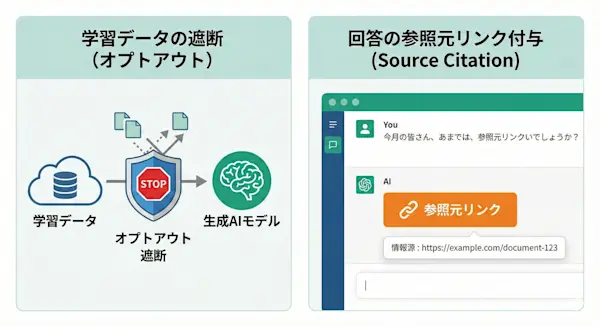
リスク1:情報漏洩(学習利用)
無料版のChatGPTなどに社内データを入力すると、そのデータがAIの学習に使われ、他社への回答として流出する恐れがあります。
【対策】
Azure OpenAI ServiceやAWS Bedrockなど、「入力データを学習に利用しない」と規約で明記されているAPIや法人向けプランを利用することは絶対条件です。
リスク2:ハルシネーション(嘘の回答)
生成AIは、データがない場合でも自信満々に嘘をつくことがあります。
業務利用では致命的です。
【対策】
RAGの強みを生かし、回答の最後に必ず参照元のドキュメントへのリンクを表示させます。
「この回答は、規定集のP.15に基づいています」と示すことで、最終確認(ファクトチェック)を人間に促す設計にします。
これを「グラウンディング(根拠付け)」と呼びます。
リスク3:権限管理
役員報酬や人事評価など、一般社員に見せてはいけないデータまで回答してしまうリスクです。
【対策】
検索システム側でアクセス権限(ACL)を管理し、「質問者の役職で見ても良いドキュメントだけを検索対象にする」フィルタリング機能を実装します。
用語解説:ハルシネーション(幻覚)
AIが事実とは異なる情報を、あたかも事実のように生成してしまう現象。
確率的に言葉を紡ぐAIの特性上、完全になくすことは難しいが、RAGによる根拠提示で抑制可能。
初期のPoC(実証実験)で、給与規定のフォルダまで検索対象にしてしまい、一般社員が役員の給与テーブルを見れてしまった…という冷や汗ものの事例を聞いたことがあります。
導入時は「AIの性能」より「データの閲覧権限設定」の方が入念なチェックが必要です。
5. 失敗しないための導入ロードマップ
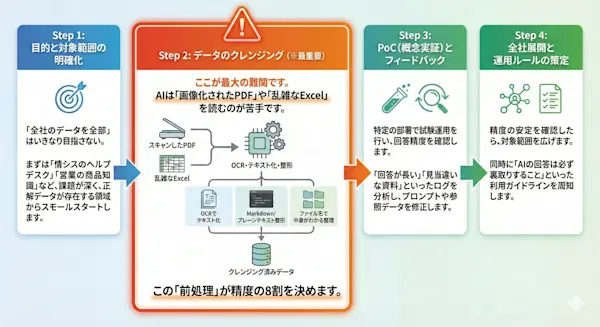
ツールを入れるだけでは成功しません。
以下のステップで着実に進めましょう。
Step 1: 目的と対象範囲の明確化
「全社のデータを全部」はいきなり目指さないでください。
まずは「情シスのヘルプデスク」「営業の商品知識」など、課題が深く、かつ正解データ(マニュアル等)が存在する領域からスモールスタートします。
Step 2: データのクレンジング(※最重要)
ここが最大の難関です。
AIは「画像化されたPDF」や「乱雑なExcel」を読むのが苦手です。
スキャンしただけのPDFはOCRでテキスト化する。
複雑なレイアウトはMarkdown形式やプレーンテキストに整形する。
ファイル名だけで中身がわかるように整理する。 この「前処理」が精度の8割を決めます。
Step 3: PoC(概念実証)とフィードバック
特定の部署で試験運用を行い、回答精度を確認します。
「回答が長い」「見当違いな資料を参照している」といったログを分析し、プロンプト(指示文)や参照データを修正します。
Step 4: 全社展開と運用ルールの策定
精度の安定を確認したら、対象範囲を広げます。
同時に「AIの回答は必ず裏取りすること」といった利用ガイドラインを周知します。
あるプロジェクトで、精度の低さに悩み抜いた結果、原因は「参照元のマニュアルが古く、矛盾だらけだった」ことでした。
AIのせいではなく、元のデータの品質が悪かったのです。
「AI導入は、自社のナレッジマネジメントを見直す良い機会になる」と痛感しました。
6. まとめ:AI時代におけるナレッジマネジメントの未来
社内ナレッジへの生成AI導入は、単なる業務効率化ツールではありません。
組織に眠る「知」を掘り起こし、全社員がトップパフォーマーの知識を活用できるようにする「組織変革」のプロジェクトです。
成功の鍵は、魔法のようなAIツール選びではなく、「AIが読みやすいようにデータを整える」という地道な準備にあります。
まずは、自社のどの部署に「探すムダ」や「属人化」が潜んでいるか、現場の声を聞くところから始めてみてはいかがでしょうか。
よくある質問(FAQ)
ここでは、社内ナレッジ×生成AIの導入に関して、よく検索される質問に回答します。
Q1. 社内情報のセキュリティはどのように担保されますか?
入力データをAIモデルの学習に利用しない(オプトアウト)設定が可能な法人向けサービス(Azure OpenAI Service等)を利用します。
また、社内ネットワーク内でのアクセス制御や、RAG構築時の参照権限管理を組み合わせることで、情報漏洩や不正アクセスを防ぎます。
Q2. 導入にはどのくらいの期間がかかりますか?
スモールスタートでのPoC(実証実験)であれば、環境構築から検証まで1〜2ヶ月程度で可能です。
全社展開には、データの整備状況にもよりますが、半年〜1年程度のロードマップを引くのが一般的です。
Q3. PDFやExcelなどのファイルも検索対象にできますか?
可能です。
ただし、画像化されたPDFはOCR処理が必要だったり、複雑なレイアウトのExcelはAIが正しく読み取れない場合があります。
精度の高い回答を得るためには、テキストデータへの変換や整形(データクレンジング)が重要になります。
Q4. AIが嘘をつく(ハルシネーション)リスクへの対策は?
RAG(検索拡張生成)技術を用い、社内データのみを根拠に回答させることが基本対策です。
さらに、回答と共に「参照元のドキュメント」を提示させるUIにすることで、ユーザー自身が情報の正確性を確認できる仕組みを取り入れます。
Q5. SaaS型ツールと自社開発、どちらが良いですか?
スピードと導入コストを優先するならSaaS型がおすすめです。
一方、独自のセキュリティ要件が厳しい場合や、特殊な社内システムとの連携が必要な場合は、APIを利用した自社開発(スクラッチ開発)が適しています。
 Aso
AsoWONQ株式会社 システムエンジニア。
2024年12月にWONQ株式会社に入社。 入社後建築企業向け業務システムや塗装企業向けの基幹システムの構築など主にバックエンド側のシステム開発に従事。 現在はフロントエンドについて学習中。
プロフィール画像から分かる通り某対戦アクションゲームではカービィを使っている。